Perplexing Config Lexeme Conflicts in the i3 Window Manager
The story of a bug, a cat, and a weekend all lining up
The Issue
In February, 2016, Github user @BobuSumisu filed [a bug report about variable expansion collisions] (https://github.com/i3/i3/issues/2235) when one variable starts with the name of another variable.
For example, say you had the following variable declarations, and an exec line
to autolaunch a program at boot:
set $shoopaloop HOWDY
set $shoop i heard you have scrumptious seafood
exec $shoopaloopOne would expect this to evaluate to exec HOWDY, however it becomes
exec i heard you have scrumptious seafoodaloop. Furthermore, given the configuration below:
set $shoop i heard you have scrumptious seafood
set $shoopaloop HOWDY
exec $shoopaloopThe correct result of exec HOWDY is achieved.
Why is it happening?
How Variables Are Parsed
To understand this bug, lets look at the parse_file
function of src/config_parser.c from the commit right before I started working on this bug. This function encapsulates a lot of logic, but the only code that is applicable to this issue is where variables are read in and stored in a list (src/config_parser.c:861887), and when that list is iterated over, replacing all occurrences of the variable with its intended value (src/config_parser.c:914-944).
The grammar for a variable declaration is essentially:
vardecl -> "set" [ \t]+ \$[\S]+ [ \t]+ [\S]+ [ \t]*
where \$ matches a literal $, \S matches any
non-whitespace character, all tokens are space or tab separated, and all configuration lines are newline separated.
When a variable is found in a config (indicated by the set keyword), a few
things happen in parse_file to verify it is syntactically correct, and then the key and value are copied to a new Variable struct which is added
to the front of a list called variables (this is important in diagnosing the
issue)
struct Variable *new = scalloc(1, sizeof(struct Variable));
new->key = sstrdup(v_key);
new->value = sstrdup(v_value);
SLIST_INSERT_HEAD(&variables, new, variables);
DLOG("Got new variable %s = %s\n", v_key, v_value);
continue;The code for substituting the variable key occurrences with their respective values is shown here:
/* Then, allocate a new buffer and copy the file over to the new one,
* but replace occurrences of our variables */
char *walk = buf, *destwalk;
char *new = smalloc(stbuf.st_size + extra_bytes + 1);
destwalk = new;
while (walk < (buf + stbuf.st_size)) {
/* Find the next variable */
SLIST_FOREACH(current, &variables, variables)
current->next_match = strcasestr(walk, current->key);
nearest = NULL;
int distance = stbuf.st_size;
SLIST_FOREACH(current, &variables, variables) {
if (current->next_match == NULL)
continue;
if ((current->next_match - walk) < distance) {
distance = (current->next_match - walk);
nearest = current;
}
}
if (nearest == NULL) {
/* If there are no more variables, we just copy the rest */
strncpy(destwalk, walk, (buf + stbuf.st_size) - walk);
destwalk += (buf + stbuf.st_size) - walk;
*destwalk = '\0';
break;
} else {
/* Copy until the next variable, then copy its value */
strncpy(destwalk, walk, distance);
strncpy(destwalk + distance, nearest->value, strlen(nearest->value));
walk += distance + strlen(nearest->key);
destwalk += distance + strlen(nearest->value);
}
}There is a lot of logistical stuff going on here that makes this code a little
hard to read, but the gist of this algorithm is to iterate through the list of
variables, hence the SLIST_FOREACH macro, from front to back, replacing
the nearest variables with their values.
So What Went Wrong?
It should be clear now that the variables are substituted in an order reversed from the order in which they were declared. With that in mind, let’s look at an example configuration that generates a happy dialog of a fish connesior visiting Los Angeles, and see how it is processed.
set $foo hey la
set $foodies i heard you have scrumptious seafood
exec echo $foo > ~/pete
exec echo $foodies >> ~/peteAfter the variables are read in, we have a list ( $foodies->i heard you have scrumptious seafood, $foo->hey la ). When
the replacement starts, we find the instances of the first variable, $foodies and
essentially rewrite them in-place (note: this doesn’t actually happen
“in-place”, but for the sake of simplicity in this article, it is a safe abstraction to make).
At this stage, we have
exec echo $foo > ~/pete
exec echo i heard you have scrumptious seafood >> ~/peteThen, we move on to the next variable in the list, $foo, and replace its
occurences, resulting in the final configuration:
exec echo hey la > ~/pete
exec echo i heard you have scrumptious seafood >> ~/peteChecking the output of cat pete verifies this:

That seemed to work well, but what if the variables were declared the other way around?
set $foodies i heard you have scrumptious seafood
set $foo hey la
exec echo $foo > ~/pete
exec echo $foodies >> ~/peteThis gives us the list of variables containing ( $foo->hey la, $foodies->i heard you have scrumptious seafood ). Let’s
see what happens when we start to replace the keys with their values, again,
starting with the first variable in the list, $foo. There is only one
instance of $foo, so there should be no issue.
exec echo hey la > ~/pete
exec echo hey ladies >> ~/peteSigh, what does cat pete have to say?
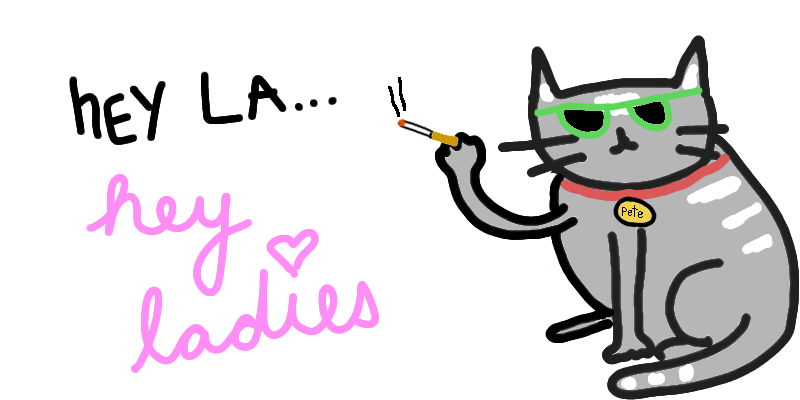
Woah woah woah…what?. Our previously sweet Ol’ Pete fled, and became a deviously effete meat head! So yeah, turns out there were two instances of
“$foo”, but one was contained in “$foodies”. At this point there’s nothing left to even do, we’ve
overwritten all of the $foo substrings in the occurrences of $foodies, leaving
just the skeezy “hey ladies” behind.
Fixing the Issue
So it seems that there are two ways we could possibly fix this, one based on whitespace, and another more subtle way. If we looked for variable occurrences that were complete tokens separated by whitespace, this would certainly solve the issue…at least in the above example. However, it is extremely common, and sometimes necessary to have variable references that are not separated by whitespace, such as:
bindsym $mod+1 workspace 1Therefore, this option is not feasible in the current context. So what does that leave us?
Longest Lexeme Based Parsing
The concept of matching on longest lexeme means that given a variable reference
in which more than one substring starting at position 0 of the name is equal to a defined variable, then it should be replaced by the one with the longest length. For example, in our running example, a reference to $foodies should not be matched with $foo, because there is a longer declared variable that (exactly) matches it $foodies. This is a pretty simple concept, and seems perfect for this scenario, but how exactly do we implement it in the context of this codebase?
Implementing Longest Lexeme Matching
Recall the example configuration:
set $foo hey la
set $foodies i heard you have scrumptious seafood
exec echo $foo > ~/pete
exec echo $foodies >> ~/peteThe variables in this configuration were correctly replaced, so what is there to
learn from it? Well, remember that the variable key/value pairs are added to the
Variables list at the front, which means that after all variable declarations were
parsed, the list had the longer lexeme at the head. When variable replacement
started, it substituted all instances of the longest variable, $foodies leaving
none for $foo to eagerly match on.
In essence, if we can ensure that our complete list of Variables is sorted with the longest key at the head and the shortest key at the tail, then we can ensure that if variables are initial substrings of another, the longer variable reference will have already been replaced, avoiding any conflict.
The i3 codebase is very elegantly designed, and a lot of decisions are made to
maintain a cohesive style, convention, and design. The initial implementation
of the Variables list uses the <sys/queue.h> SLIST singly-linked list macros
as its structure. Obviously it seemed like a perfect choice to insert in O(1)
on a tried and true data structure, but unfortunately this would have to be
changed in one of two way: either change the data structure and its many
interactions to a better suited
sorted list, or use the SLIST and sacrifice O(1) in exchange for minimal codebase changes. Since variable parsing only ever happens once, is relatively lightweight, and generally will not have a sufficiently large amount of variables to work with, I opted for the latter approach, wherein I compared the length of each new variable key to those of the current values; inserting before any keys that are shorter, or, simply sorting the list by length upon insertion. If the new variable key is longer than all others it becomes the new front of the list. The new code is shown below, if you compare it to the original Variables insertion code, you will find that consists of actually very few changes.
struct Variable *new = scalloc(1, sizeof(struct Variable));
struct Variable *test = NULL, *loc = NULL;
new->key = sstrdup(v_key);
new->value = sstrdup(v_value);
/* ensure that the correct variable is matched in case of one being
* the prefix of another */
SLIST_FOREACH(test, &variables, variables) {
if (strlen(new->key) >= strlen(test->key))
break;
loc = test;
}
if (loc == NULL) {
SLIST_INSERT_HEAD(&variables, new, variables);
} else {
SLIST_INSERT_AFTER(loc, new, variables);
}
DLOG("Got new variable %s = %s\n", v_key, v_value);
continue;feel free to contact me with any comments or corrections via the options listed at the bottom of the page.
